Підписуйтеся на наш телеграм канал!

Співзасновник OpenAI заявив, що для навчання ШІ більше немає даних
Співзасновник OpenAI Ілля Суцкевер заявив, що для подальшого навчання штучного інтелекту компанія зіштовхується з нестачею даних. Він підкреслив, що сучасні моделі ШІ, такі як GPT‑4, уже використовують величезні обсяги текстової інформації, доступної в інтернеті, і доступ до нових релевантних даних стає дедалі обмеженішим.
За словами фахівця, проблема не лише в кількості, а й в якості даних. “Більшість відкритих ресурсів уже використані для навчання, а створення нових, більш специфічних наборів даних вимагає великих зусиль і ресурсів”, — зазначив топменеджер.
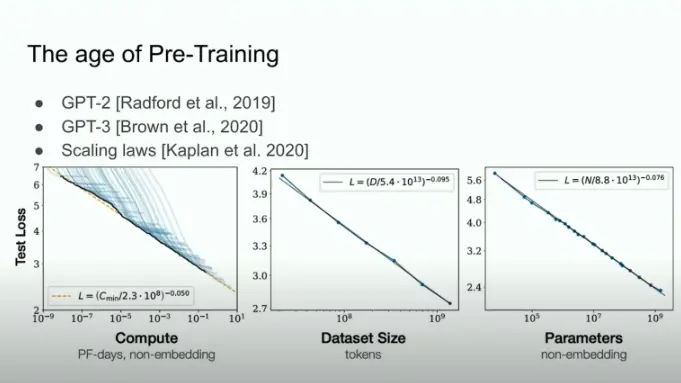
Суцкевер також наголосив, що одним із можливих рішень є генерація синтетичних даних самими моделями ШІ, однак це підходить не для всіх завдань і може призводити до нових викликів — упередженості LLM (великих мовних моделей — ред.) і низької точності результатів.
Фахівці вважають, що у найближчі роки індустрія ШІ може зіткнутися з необхідністю змінювати підходи до навчання моделей, зокрема більше фокусуючись на оптимізації алгоритмів і покращенні ефективності роботи з уже наявними даними. Це може стати новим етапом розвитку, який потребуватиме тісної співпраці дослідників, бізнесу й регуляторів.